机器学习中,模型遵循”奥卡姆”剃刀原理,同等效果中,简单的模型更接近事实。模型既可能出现欠拟合,也可能出现过拟合,评价一个模型好坏的指标是什么?如何去做?
数据集合
通常将数据集合分为训练集,测试集,验证集。训练集用于训练模型参数,测试集用于比较测试模型的好坏,测试集中的样本应尽可能不出现在训练集中,这样才能达到测试的目的(试想考试试题若与平时练习题一样,考试还有什么效果)。测试集中误差我们称为测试误差,当训练集和测试集的划分不同时,会得到不同的测试误差,所以一般多次划分训练集和测试集,再将多次测得的测试误差进行平均,选取更优的模型,这里所说的模型是指模型种类,如二次模型,三次模型,对数模型等。而验证集验证模型在实际中的使用效果,验证集测得的误差成为泛化误差。
评估方法
留出法
将数据集D划分为两个互斥的集合,一个用作训练集S,一个用作测试集T,训练集和测试集要保持样本的一致性,可通过分层抽样。
交叉验证法
将数据集划D分为k个大小相似的互斥子集,即$D = D_1 \bigcup D_2 \bigcup \dots \bigcup D_k, D_i \bigcap D_j = \varnothing(i \ne j) $,每个子集$D_i$都尽可能保持数据分布的一致性,然后每次使用k-1子集的并集作为训练集,余下的作测试集,这样可以获得k组测试集/测试集,这样可以进行k次训练和测试,返回结果为k次测试结果的平均。显然,交叉验证法评估结果的稳定性和保真性在很大程度上取决于k的大小,为强调k的重要性,我们称之为”k折交叉验证法”,k常用取值为10.当k值确定后,k个子集仍有多种取法,也要多次随机选取,常见的有”10次10折交叉验证”。

留一法
自助法
摘抄自周志华«机器学习»:

偏差方差分解
这里的D是训练集。
偏差-方差分解试图对学习算法的期望泛华错误率进行拆解,我们知道,算法在不同的训练集上学习到的结果可能不同。对于测试样本 $x$ ,令 $y_D$ 为$ x $在数据集中的标记(由于噪声的存在,可能$y_D \ne y$),$y $为 $x $的真实标记,$f(x;D)$ 为训练集D上学得模型$f $在$x $上的预测输出,以回归任务为例,学习算法的期望预测为:
使用样本相同的不同训练集产生的方差为:
噪声为:
期望输出与真实标记的差别称为偏差 :
假定噪声期望为0,即:
对期望泛化误差进行分解:
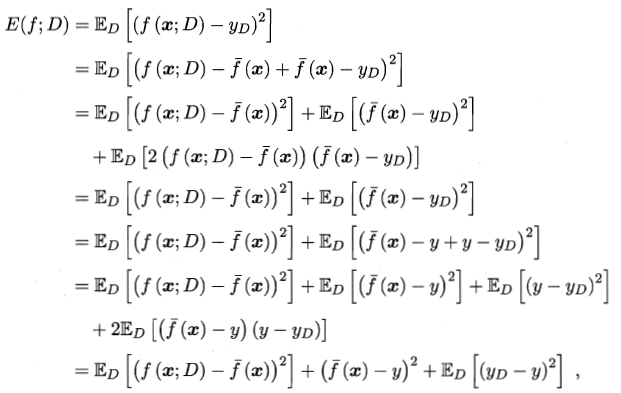
也就是说,泛华误差可以分解为偏差、方差和噪声之和。偏差度量学习算法的期望预测和真实结构的偏离程度,即刻画了算法本身的拟合能力;方差度量同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响;噪声表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即学习问题本身的难度。