图像检测,分类并找出具体位置,传统的做法为HOG+SVM或类似,人为提取特征并训练,检测时由于图片大小不一,需要多尺度检测,对重叠区域 再作处理,如扩大。图像的复杂性在于不同光照,颜色北京,深度学习图像检测成为主流。
two stage
候选区域+深度学习,包括R-CNN,Fast R-CNN,Faster R-CNN
R-CNN由三个步骤组成,Selective Search + CNN + SVM,找到的最好的一篇中文翻译就是这个, Selective Search选出越2k个候选框,CNN提取特征,SVM分类, bounding box regression,需要理解图像识别是针对候选框进行,可以识别一幅图像 上的多个物体。
Fast R-CNN之前有SPPnet,ZFnet,解决的问题是一次性提取候选框的特征,输入图像大小可以不一,多任务训练,SVD分解简化连接层运算量。具体可以参考 上一个链接的同作者的另一篇文章。顺便膜拜一下,互联网的世界里到处都是绝世高手。
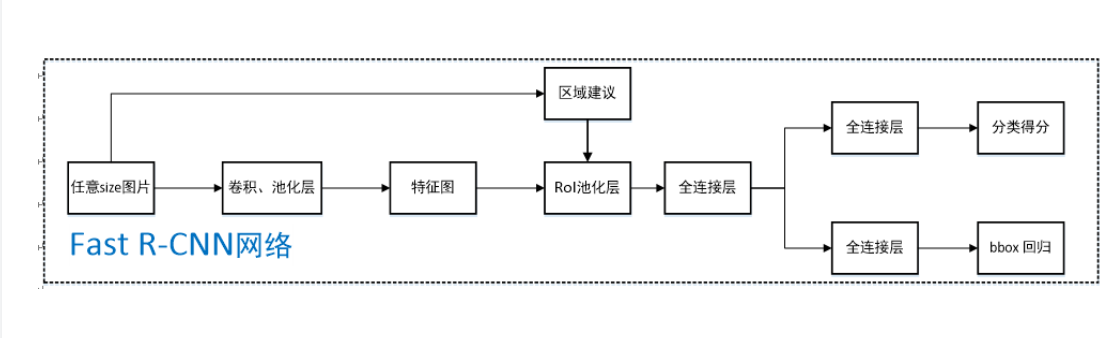
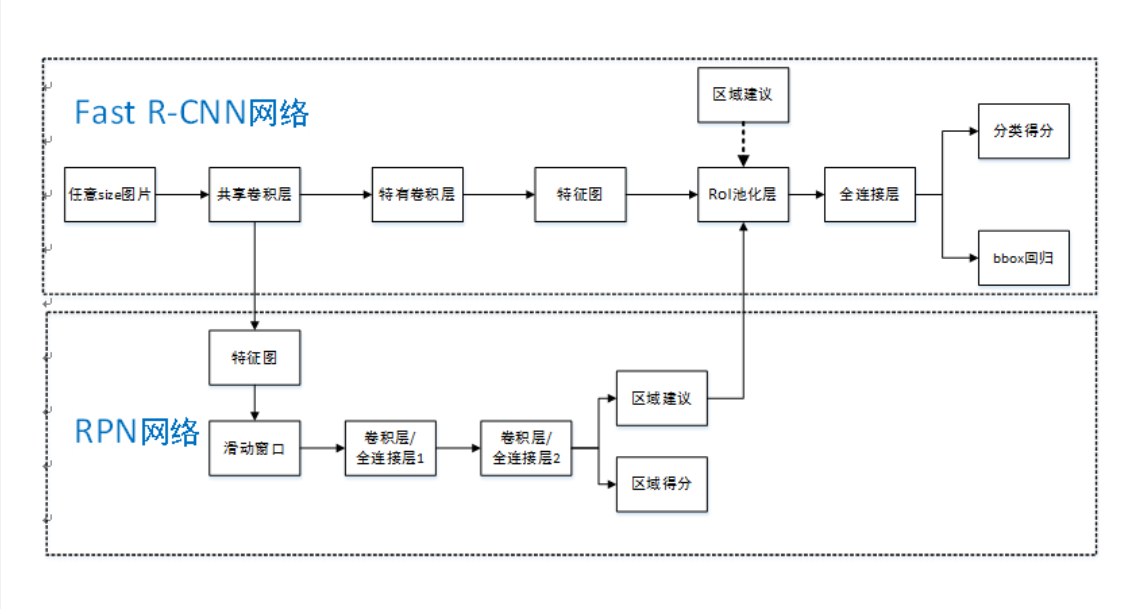
Faster R-CNN进一步解决候选框的生成,用RPN(Region Proposal Network)网络生成。
one stage
yolo v1,v2,v3和ssd
yolo没有region proposal,计算量降低,但准确度降低
ssd采用fpn(特征金字塔)的思想。
retinanet采用focal loss损失函数,形式简单,但体现了对目标识别准确率低的最根本原因的认识。
detectron是facebook开源的目标检测库,基于python和caffe2,实现了大部分目标检测算法。
squeeze and excitation network
学习通道间的关系,关注有用特征抑制无用特征(重要的通道赋予大的权重)