卷积神经网络的反向传播算法推导中的注意事项。
BP
可以将普通的神经网络称为广义神经网络,其BP算法称为广义上的BP算法。卷积神经网络的反向传播本质上是和广义BP一样的,可以将卷积神经网络的结构画成广义上的神经网络。
卷积神经网络结构
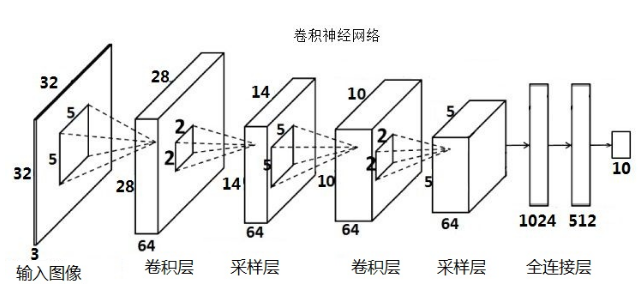
式中$x_j^l$表示下一层特征,$M_j$表示该下层特征是由相关的上层特征组合变换而来。卷积其实就是提取特征,之后可以继续卷积,相当于在原始特征上合成复杂特征。
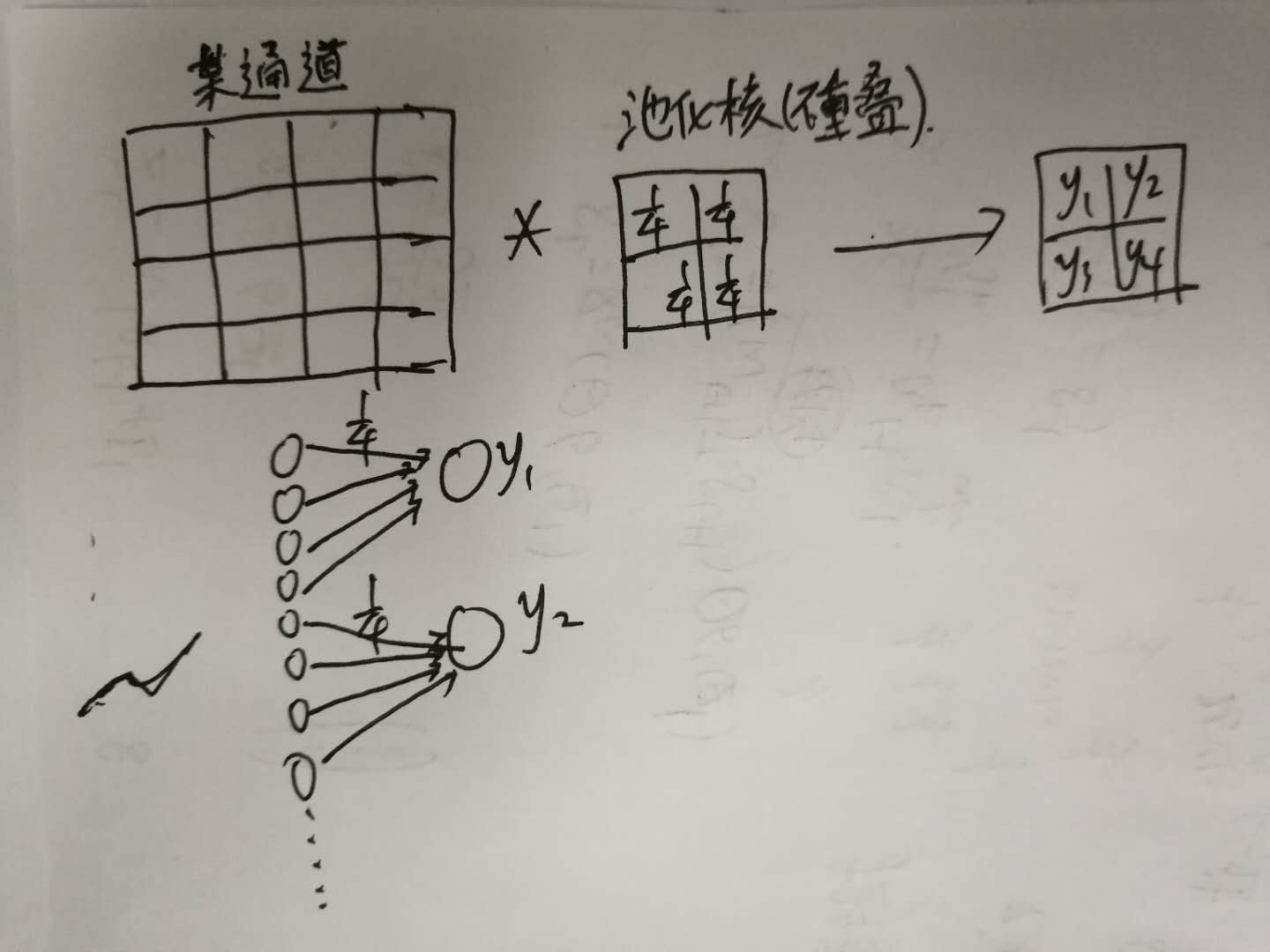
当对反向求导有不清晰的地方时,可以画出对用的广义神经网络图,如均匀池化等效于下图:
Batch Normalization(BN)批标准化
Internal Covariate Shift
Why BN?好了,现在才是重头戏--为什么要用BN?BN work的原因是什么?说到底,BN的提出还是为了克服深度神经网络难以训练的弊病。其实BN背后的insight非常简单,只是在文章中被Google复杂化了。首先来说说“Internal Covariate Shift”。文章的title除了BN这样一个关键词,还有一个便是“ICS”。大家都知道在统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如,transfer learning/domain adaptation等。而covariate shift就是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同,即:对所有,,但是. 大家细想便会发现,的确,对于神经网络的各层输出,由于它们经过了层内操作作用,其分布显然与各层对应的输入信号分布不同,而且差异会随着网络深度增大而增大,可是它们所能“指示”的样本标记(label)仍然是不变的,这便符合了covariate shift的定义。由于是对层间信号的分析,也即是“internal”的来由。那么好,为什么前面我说Google将其复杂化了。其实如果严格按照解决covariate shift的路子来做的话,大概就是上“importance weight”(ref)之类的机器学习方法。可是这里Google仅仅说“通过mini-batch来规范化某些层/所有层的输入,从而可以固定每层输入信号的均值与方差”就可以解决问题。如果covariate shift可以用这么简单的方法解决,那前人对其的研究也真真是白做了。此外,试想,均值方差一致的分布就是同样的分布吗?当然不是。显然,ICS只是这个问题的“包装纸”嘛,仅仅是一种high-level demonstration。那BN到底是什么原理呢?说到底还是为了防止“梯度弥散”。关于梯度弥散,大家都知道一个简单的栗子:。在BN中,是通过将activation规范为均值和方差一致的手段使得原本会减小的activation的scale变大。可以说是一种更有效的local response normalization方法(见4.2.1节)。来自知乎回答
BN中会有一个放缩和平移,用途是可以适当还原当前层所学习到的表征,避免完全损坏当前层的学习。
